SQL Server Index analyse
I denne artikel giver jeg gode råd til hvordan du nemmest og mest overskueligt laver en index analyse, som er til gavn for din organisation, så I sikrer at tiden bruges mest fordelagtigt.
Du kender måske udfordringer som:
- Hvor skal du starte på et stort Enterprise system?
- Hvordan holder du øje med om de nye index gør en forskel?
- Hvordan får du et overblik over eksisterende og index forslag fra SQL Serveren?
Resultatet af denne artikel er et script som giver en oversigt over manglende og eksisterende index som forhåbentlig vil hjælpe dig i gang med dit index analyse arbejde.
Ofte er det svært at planlægge index, når man udvikler en SQL database eller projekter herpå. Der er mange faktorer, der spiller ind. Man har måske et forventet brugsmønster og designer index efter bedste evne, men det er utrolig svært uden at kende det faktiske brugsmønster.
Et typisk eksempel herpå: Systemet tages i brug og der videreudvikles på systemet. Vores brugere siger at deres rapport kører langsomt, så vi opretter et index, der passer på rapportens SQL forespørgsel. Vores system vokser og det bliver svært for os at overskue hvilke index vi har, hvilke der bruges og hvilke som foreslås af SQL Serveren, der vil give værdi at oprette.
Gevinst
Det er der mange valide løsninger på. Jeg har her valgt at benytte en blanding af de oprettede index sammenholdt med de forslag SQL Serveren kommer med og så en beregnet ”gevinst”.
"Formålet med index er at hjælpe SQL Serveren med at finde data hurtigst muligt, så vi belaster og låser systemet minimalt – Derfor er det også en af de vigtigste vedligeholdelsesopgaver at analysere index" Citat SQL Specialist - Developer Jacob Saugmann
SQL Serveren indeholder en stor mængde statistik data (Meta data) vi kan benytte, når vi skal analysere bl.a. index. Der indsamles statistik data fra at SQL Serveren startes. Disse gemmes til serveren genstartes.
Vi har f.eks. mulighed for at se hvilke index vi har, hvilke kolonner der indgår, index typen, og ikke mindst hvordan de benyttes af Query Optimizeren (user seek, user scan, user lookup). VI kan tage udgangspunkt i nedenstående DMV for at får disse oplysninger.
Se detaljer på docs: Docs link
SQL Serveren indsamler også missing index detaljer, her kan vi tage udgangspunkt i denne DMV.
Se detaljer på docs: Docs link
Heri gemmes alle de index som SQL Serverens Query Optimizer har vurderet kunne være gavnligt for vores SQL forespørgsel. Her er det vigtigt at bemærke, at missing index detaljer ikke kigger på tværs af databasen, men udelukkende på det afviklende SQL Query.
Vi skal derfor ikke i blinde oprette de missing index forslag vi får; vi er nødt til at sammenholde dem med de andre oprettede index på tabellen og eventuelt andre missing index. Måske kunne vi omskrive et nonclustered index og så inkluderer nogle af de manglende kolonner fra vores missing index detaljer.
Måske skal vi slet ikke oprette det, da SQL Query, hvor index er foreslået til, kun benyttes meget sjældent og ikke er forretningskritisk. Risikoen er også, at vi får oprettet alt for mange index på tabellen. Selv om index har en positiv effekt, når vi forespørger vores SQL Server, så er der også en pris, der skal betales, nemlig i forbindelse med insert, update og delete operationer.
"Generelt anbefales det at have maks. 5-7 index på en tabel, alt efter brug. (Der er systemer hvor flere index end det giver god mening)" - Citat SQL Specialist - Developer Jacob Saugmann
Hvordan kan man så komme i gang med at analysere index på SQL Serveren?
Vi kunne f.eks. kigge på de mest læsetunge SQL Query (logical reads) på serveren og så analysere de index der benyttes. Det er bestemt en valid indgangsvinkel, men også en lidt tung vej igennem en SQL Server med tusinder af SQL forespørgsler.
Jeg synes det er rart med et overblik, hvor jeg kan sammenholde alle index, der er oprettet, inklusiv de kolonner der indgår, mod alle de index forslag SQL Serveren har fundet (missing index).
Jeg har alle informationerne jeg skal bruge, nu skal jeg bare spørge SQL Serverens DMV/DMF’er. Husk at når SQL Server genstartes så nulstilles den indsamlede statistik også. Så derfor skal man altid kigge på hvor gammel metadata er.
Vi skal gerne have så valid statistik som muligt, og det får vi når SQL Serveren har kørt i nogen tid (uger/måneder).
"Tip: se på hvornår tempdb er oprettet for at finde ud af hvor gammel statistik er: SELECT Create_date FROM sys.databases WHERE name = ‘tempdb’"- Citat SQL Specialist - Developer Jacob Saugmann
Jeg kan så lave en liste, der viser index og deres brugsmønster, kolonner, type, inklusiv alle de forslag SQL Serveren har. Det giver mig et overblik, hvor jeg lettere kan kigge på hele min SQL Server database og finde de index, der ikke bruges. Eller dem, som jeg ved at ændre i og f.eks. inkludere ekstra kolonner, kan dække flere forespørgsler.
Det er vigtigt, efter analysen og når de tilrettede/nye index er oprettet, at vende tilbage til index analysen efter nogen tid, da ændringerne der laves, kan betyde at andre index ikke længere benyttes og derfor skal nedlægges. Eller at de index vi har oprettet, ikke bliver brugt helt sådan som vi i teorien forventede.
Da missing index detaljer slettes for de tabeller hvor vi laver f.eks. nye index, kan det være en ide at gemme udtrækkene enten i en tabel eller i Excel-ark, så vi kan se om der kommer de samme forslag igen og igen.
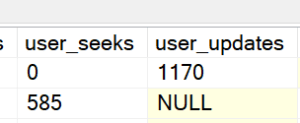
Jeg har lavet følgende script, som kan ses i bunden af denne artikel. Den giver mig følgende output: (tabellen er rettet til så den kan være på siden)


Her kan jeg se at der er 2 index på tabellen, hvilken type det er, at der er 2 forslag og informationer om hvilke kolonner, der indgår i både index forslaget og de eksisterende index. Desuden er der en beregnet værdi, som er en anslået værdigevinst ved at oprette det manglende index. Desuden indeholder resultatet også statistik over hvordan de eksisterende index benyttes. Kig her efter user updates, hvis det er højere antal updates end antallet af gange indexet er brugt (user_seek, user_scan) så giver det formentlig ikke så meget værdi at beholde.
Benyt gerne scriptet her i bunden og tilret det som du ønsker.
Tips
Jeg vil også gerne give et par generelle råd i forbindelse med index:
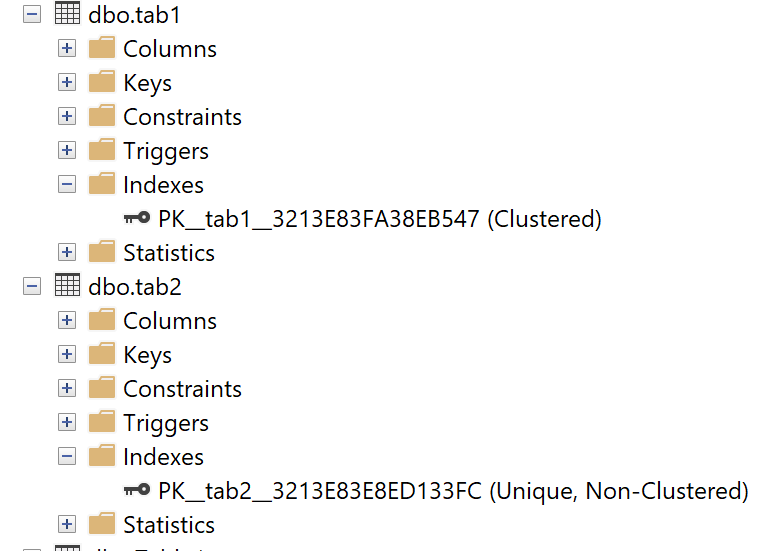
Skal din primary key ikke være din cluster key, så husk at angive NONCLUSTERED når du opretter den, ellers bliver det din cluster key
- CREATE TABLE tab1(
- id INT IDENTITY(1,1) PRIMARY KEY,
- Name_Char CHAR(1)
- )
- CREATE TABLE tab2(
- id INT IDENTITY(1,1) PRIMARY KEY NONCLUSTERED,
- Name_Char CHAR(1)
- )
Hvis dine Clustered index er unikke så angiv det, når du opretter index.
- CREATE CLUSTERED INDEX..
- CREATE UNIQUE CLUSTERED INDEX..
Ved ikke at angive at det er unikt, kan det betyde at Query Optimizeren vælger en hash match join i stedet for den noget hurtigere Merge join, når clustered index key benyttes i joins. Desuden kan dubletværdier indsættes og der tilføjes en uniqueifyer på kolonnen.
Et godt råd: Inkludér aldrig for mange kolonner i dit nonclustered index included columns, det giver ikke mening. Så kan det clustered index benyttes i stedet for.
Index analyse kan være en lidt svær opgave at komme i gang med, men forhåbentlig med dette script kan du få et overblik, som kan hjælpe dig i gang med at analysere dine index på dit SQL Server miljø.
Vi hjælper selvfølgelig også gerne til, du skal bare tage fat i mig eller en af mine dygtige kollegaer i Unit IT, kontakt os gerne på tlf.: 88 333 333.
