Nonclustered Index
I sidste artikel skrev jeg lidt om heap table vs clustered table; altså en tabel med et clustered index på.
Grunden til, at vi bruger index er, for at have en hurtigere og mere direkte vej til data. Når data er sorteret, er det markant hurtigere for SQL Serveren at finde data frem igen, da der læses færre pages, det fylder mindre i bufferen og derved er også mindre af tid tabellen blokeret.
Når vi har data sorteret efter en cluster key (den eller de nøgler vi bruger til at fortælle hvordan data skal sorteres) giver det os hurtig adgang til data. Dog kunne vi godt bruge en alternativ sortering af data, da et clustered index fortæller om den fysiske sortering af data, helt ned på vores 8kb pages ned på disken. Som vist i sidste artikel er det ikke muligt, at have mere end et clustered index pr. tabel. Det er her hvor NONCLUSTERED index kommer ind i billedet.
Et nonclustered index gemmer data på samme måde som et clustered index. Dog med den markante forskel, at et nonclustered index er en ”kopi” af vores data på nye pages med en ny sortering. Et nonclustered index behøver ikke at indeholde alle vores kolonner fra tabellen, men kan nøjes med dem vi skal bruge i forbindelse med forespørgsel af data via SQL. Det vil altså sige, at vi kan lave et nonclustered index på en tabel, hvor vi sorterer data anderledes end vores cluster key, som vi definerer i vores clustered index, og kun indeholder en delmængde af de kolonner vores tabel har.
Vi kan godt have flere end et nonclustered index pr. tabel, også selvom tabellen har et clustered index. Typisk bruges nonclustered index til at understøtte de mest forretningskritiske SQL forespørgsler, så de går super hurtigt.
Syntaxen er:
CREATE NONCLUSTERED INDEX <name> ON <TABEL> (<key>, [<key>…]) INCLUDE (<column>, <column> …. )Angiv unikt navn
Vi skal give det nonclustered index et unikt navn. Jeg bruger tit idx_tabelname_keycolumn som navngivnings syntax, men her er ingen regler, dog skal indexnavnet være unikt på tværs af hele databasen.
Når vi skal angive key columns skal vi tænke os godt om. Ret ofte er der flere keycolumns på nonclustered index. Og her er rækkefølgen utrolig vigtig, da data bliver sorteret efter key1, så key2 osv. Du skal vælge den kolonne, der sorterer FLEST data fra. I SQL sprog hedder det, at kolonnen har en lav density, dernæst den der sorterer næstflest fra osv. På den måde vil SQL Serveren hurtigt kunne indsnævre de pages, der indeholder det data den skal bruge.
Et lille eksempel:
Jeg opretter følgende tabel, bemærk Id kolonnen er primary key clustered, som laver et clustered index på den kolonne:
CREATE TABLE Venner(
Id INT IDENTITY(1,1) PRIMARY KEY CLUSTERED,
Fornavn NVARCHAR(120),
Efternavn NVARCHAR(120),
Postnummer VARCHAR(4)
)Jeg indsætter data fra Adventureworks databasen med følgende SQL forespørgsel:
INSERT INTO Venner (Fornavn,Efternavn,Postnummer)
SELECT FirstName,
LastName, '8220' as postnummer
FROM AdventureWorks.Person.PersonJeg opretter et nonclustered index og bruger efternavn kolonnen som key column (sorterings rækkefølgen)
CREATE NONCLUSTERED INDEX idx_venner_Efternaven ON dbo.Venner(Efternavn)Jeg kan nu i server exploren i SSMS se der er 2 index på tabellen et clustered og mit nonclustered
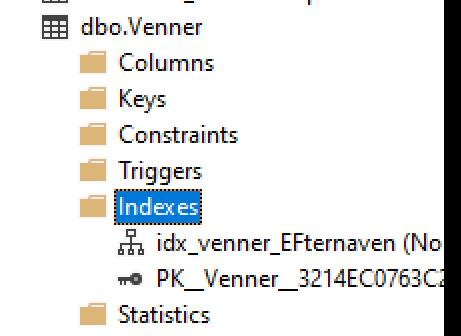
Jeg kan nu køre følgende SQL forespørgsel og bemærk at det nonclustered index benyttes:
SELECT Efternavn,
Fornavn
FROM Venner
WHERE Efternavn = 'Adams'
Keylookup!
Her kommer der dog en ekstra operator på, en keylookup!, og de 98.2%, som der står over den fortæller at det er den ”mest kostbare/tungeste” operation i vores forespørgsel. I en senere artikel kan jeg komme ind på executionplans og cost, men det er ude af scope for denne artikel. Forhold dig blot til at hver operator har en cost i forhold til de andre operatorer. Jo højere costen er, jo tungere er den del af query.
Hvordan løser vi det? Først skal vi lige se hvad en keylookup er. Når det nonclustered index bliver oprettet har det altid en pointer tilbage til tabellen det er oprettet på. Så hvis vi har taget 2 kolonner med i vores nonclustered index fra vores tabel så vil hver ”række” på vores page pege unikt tilbage på samme række i vores tabel. For en heap tabel er det en RID (row identifier) og hvis det er en clustered table, så er det cluster key, der er pointeren. Årsagen til det er, at SQL Serveren skal have mulighed for at lave opslag i tabellen hvis nu der skal bruges flere kolonner i SQL forespørgslen end dem, der er i det nonclustered index. SQL Serveren laver derfor et keylookup for at finde data i tabellen.
Så tilbage til vores keylookup, og hvad vi kan gøre ved det. For her bliver vores nonclustered index nemlig rigtig smart. Vi har nemlig mulighed for at ”include” kolonner i indexet, dem sætter vi ind i INCLUDE() delen af create statementet, og her har rækkefølgen ingen betydning for sorteringen som rækkefølgen har i vores key columns. Ved at gøre dette, så inkluderes værdien af den/de kolonner sammen med key column og derved behøver SQL Serveren ikke lave et opslag på tabellen, da alt det data, der skal bruges allerede er i det nonclustered index.
Hvis vi opretter vores nonclustered index og inkluderer fornavn, så behøver SQL Serveren ikke lave keylookup over i tabellen, men kan blot benytte det nonclustered index.
CREATE NONCLUSTERED INDEX idx_venner_Efternaven ON dbo.Venner(Efternavn) INCLUDE (Fornavn)vi kører vores forespørgsel fra før, får vi nu et index seek på det nonclustered index og INGEN keylookup da data ligger inkluderet i det nonclustered index, det er smart 😊
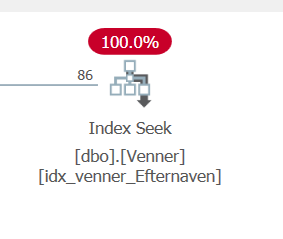
Prisen for nonclustered index
Vær dog opmærksom på, at nonclustered index også har en pris. Bl.a. ved indsættelse, opdatering eller sletning af data, her skal det nonclustered index også opdateres. Hvert nonclustered index tager plads, hvor meget afhænger af hvilke kolonner du har i dit nonclustered index, og hvad deres data type er.
Index skal også vedligeholdes, det kommer jeg tilbage til i en senere artikel, men du får lidt ekstra arbejde som DBA.
En tommelfingerregel vi plejer at benytte er: op til 5 nonclustered index på en tabel er fint. Mellem 5-8 så skal du have rigtig gode argumenter og flere end det skal du helst undgå. Som med alle andre tommelfingerregler på en SQL Server, så afhænger det af mange ting. Er du i tvivl om du har for mange index på en tabel, så tag fat i os i Unit IT.
Nonclustered index er et super værktøj, når vi snakker performanceoptimering af SQL Server. Husk blot på at du kun skal oprette de indexes, der er nødvendige for din performance, igen spørg – vi hjælper gerne.
Der er et par ting du skal undgå, når du opretter nonclustered index:
Lad være med at tage alle kolonner med ind i dit index. Du får en 1:1 kopi, hvilket betyder at du i realiteten har en tabel, der fylder dobbelt op, da den er sorteret på 2 forskellige måder.
Lad være med at inkludere for mange kolonner. Hvis index bliver for ”tungt”, så kan SQL Serveren godt vælge at bruge det clustered index i stedet for.
Lad være med at tage clusterkey med fra dit clustered index i et nonclustered index. Husk cluster key er der allerede som pointer over til tabellen.
Jeg vil om ganske kort tid skrive om endnu en mulighed, vi har med de nonclustered index. Vi kan nemlig filtrere rækker fra så det nonclustered index kun indeholder præcis de rækker, der er relevante for os.
Tak fordi du læste med. Har du spørgsmål til dine SQL forespørgsler, performance eller andet SQL relateret så tag endelig fat i mig eller en af mine dygtige kollegaer i Unit IT. Ring til os på tlf.: 88 33 33 33.
