
Anyways noget af det vi stødte på, var UNIQUEIDENTIFIERS som id-kolonne i tabellerne. Dette ser jeg tit når tabellen er skabt af .net udviklere, da netop det at have en unik nøgle giver god mening – MEN man tænker ikke konsekvensen igennem for SQL Serveren.
Lad mig prøve at illustrere:
Jeg laver en tabel med 3 kolonner som denne, bemærk at id-kolonnen er en uniqueidentifier:
CREATE TABLE dbo.uniqueid(
id uniqueidentifier DEFAULT NEWID(),
chartext CHAR(20),
number INT
);
GOJeg indsætter lidt dummy data:
SET NOCOUNT ON
GO
INSERT INTO dbo.uniqueid (chartext, number)
VALUES(REPLICATE('a',20), RAND() * 9 + 1)
GO 2000Og herefter opretter jeg et clustered index, hvilket er meget almindeligt at have på id kolonnen:
CREATE CLUSTERED INDEX idx_uniqueidentifier ON dbo.uniqueid(id)
GODet er meget lige til, nu kigger jeg på index stats for at se fragmenteringen:
SELECT i.name,
ixs.avg_fragmentation_in_percent,
ixs.page_count
FROM sys.indexes i
CROSS APPLY sys.dm_db_index_physical_stats(DB_ID(),i.object_id, i.index_id, NULL, NULL) AS ixs
WHERE i.name = 'idx_uniqueidentifier'Det giver dette resultat:

Så kører jeg scriptet der indsætter 2000 rækker igen:
INSERT INTO dbo.uniqueid (chartext, number)
VALUES(REPLICATE('a',20), RAND() * 9 + 1)
GO 2000Og lad os endnu engang kigge på index stats:

Bemærk fragmenteringen!
Hvorfor sker det? et clustered index definerer den fysiske sorteringsorden i tabellen og hvis vi kigger på en uniqueidentifier så ser den sådan her ud:
EBA6746F-8655-4D2B-B080-A3E96D818753
Denne sekvens skal sorters ind på rette plads i indexet, hvilket kan være hvor som helst da der ikke er nogen sorteringsorden på en uniqueidentifier. Jeg tager lige 3 ud her:
SELECT NEWID() AS a
SELECT NEWID() AS b
SELECT NEWID() AS c
Bemærk at der ikke er nogen let måde at sortere det på, samt at disse 3 kan meget vel havne 3 meget forskellige steder i index, hvor der højest sandsynligt skal allokeres plads på en page (8 kb page hvor data gemmes). Dette skaber en fragmentering af indexet, så hvert insert skaber en ret heftig fragmentering af indexet.
Hvis du ikke kan undgå at bruge uniqueidentifiers, så er der et alternativ som ikke er helt så slemt.
NEWSEQUENTIALID
Jeg gør det samme som oven for, men med en enkelt ændring; i stedet for defaultværdien på id kolonnen tilføjer jeg NEWSEQUENTIALID() som værdi:
CREATE TABLE dbo.seq_uniqueid(
id uniqueidentifier DEFAULT NEWSEQUENTIALID(),
chartext CHAR(20),
number INT
);
GO
SET NOCOUNT ON
GO
INSERT INTO dbo.seq_uniqueid (chartext, number)
VALUES(REPLICATE('a',20), RAND() * 9 + 1)
GO 2000
CREATE CLUSTERED INDEX idx_seq_uniqueidentifier ON dbo.seq_uniqueid(id)
GO
Endnu engang indsætter jeg 2000 rækker:
INSERT INTO dbo.seq_uniqueid (chartext, number)
VALUES(REPLICATE('a',20), RAND() * 9 + 1)
GO 2000Og kigger igen på fragmenteringen:

Bemærk denne gang er der kun 16% fragmentering mod 97% før.
Årsagen til dette er at der laves en sekvens af ideer hvor størstedelen at stringen er ens og kun lidt ændres. Dette gør, at SQL Serveren har langt lettere ved at putte data ind i ”bunden” af tabellen i stedet for et nyt sted hver gang.
Så forskellen på de 2 ser sådan her ud:
NEWID() NEWSEQUENTIALID

Til sammenligning så laver jeg lige samme øvelse bare med en int som id kolonne:
CREATE TABLE dbo.intid(
id INT IDENTITY(1,1),
chartext CHAR(20),
number INT
);
GO
SET NOCOUNT ON
GO
INSERT INTO dbo.intid (chartext, number)
VALUES(REPLICATE('a',20), RAND() * 9 + 1)
GO 2000
CREATE CLUSTERED INDEX idx_intid ON dbo.intid(id)
GOSå lad os kigge i index stats igen..

Nu indsætter jeg 8000 rækker igen:
INSERT INTO dbo.intid (chartext, number)
VALUES(REPLICATE('a',20), RAND() * 9 + 1)
GO 8000Og kigger igen i index stats:
.png?width=561&height=129&name=2020-08-20-21_43_45-solution1-miscellaneous-files-sqlquery5sql-local-demo-winauth-micro%20(1).png)
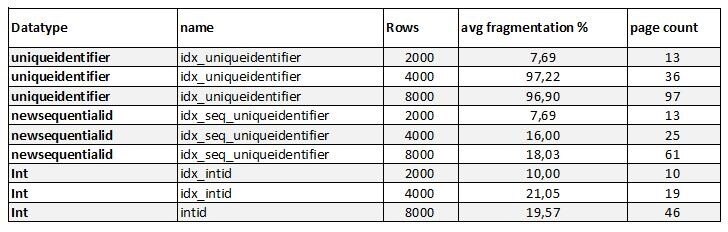
Og hvis vi sammenligner de 3 forskellige datatyper efter 8000 rækker er indsat:
Uniqueidentifier (newid())

Uniqueidentifier(NEWSEQUENTIALID())

Int

Umiddelbart er de 2 sidste ens.. og dog.. for bemærk page_count (bemærk det for alle 3 datatyper), en uniqueidentifier tager flere bytes som datatype end en int. Derfor bliver der brugt 61 pages mod 46 for en int. Hvis du absolut skal brug en uniqueidentifier som datatype, så brug NEWSEQUENTIALID() som default værdi. Men kan du ”nøjes” med en integer så sparer du plads, for husk på at den kolonne du vælger som cluster key også bliver kopieret ud i dine nonclustered index (som reference tilbage til dit clustered index hvilket derved også gør dit nonclustered index større!).
Her er en oversigt over de 3 forskellige datatyper ved hhv. 2000, 4000 og 8000 rækker:
Du kan læse mere om de brugte datatyper her:
Uniqueidentifier - 16 bytes (https://docs.microsoft.com/en-us/sql/t-sql/data-types/uniqueidentifier-transact-sql?view=sql-server-ver15)
Int – 4 bytes (https://docs.microsoft.com/en-us/sql/t-sql/data-types/int-bigint-smallint-and-tinyint-transact-sql?view=sql-server-ver15)
Tak fordi du læste med. Som altid så er du velkommen til at kontakte mig eller en af mine dygtige kollegaer i Unit IT på tlf.: 88 333 333, hvis du har spørgsmål eller udfordringer med dit SQL miljø.


