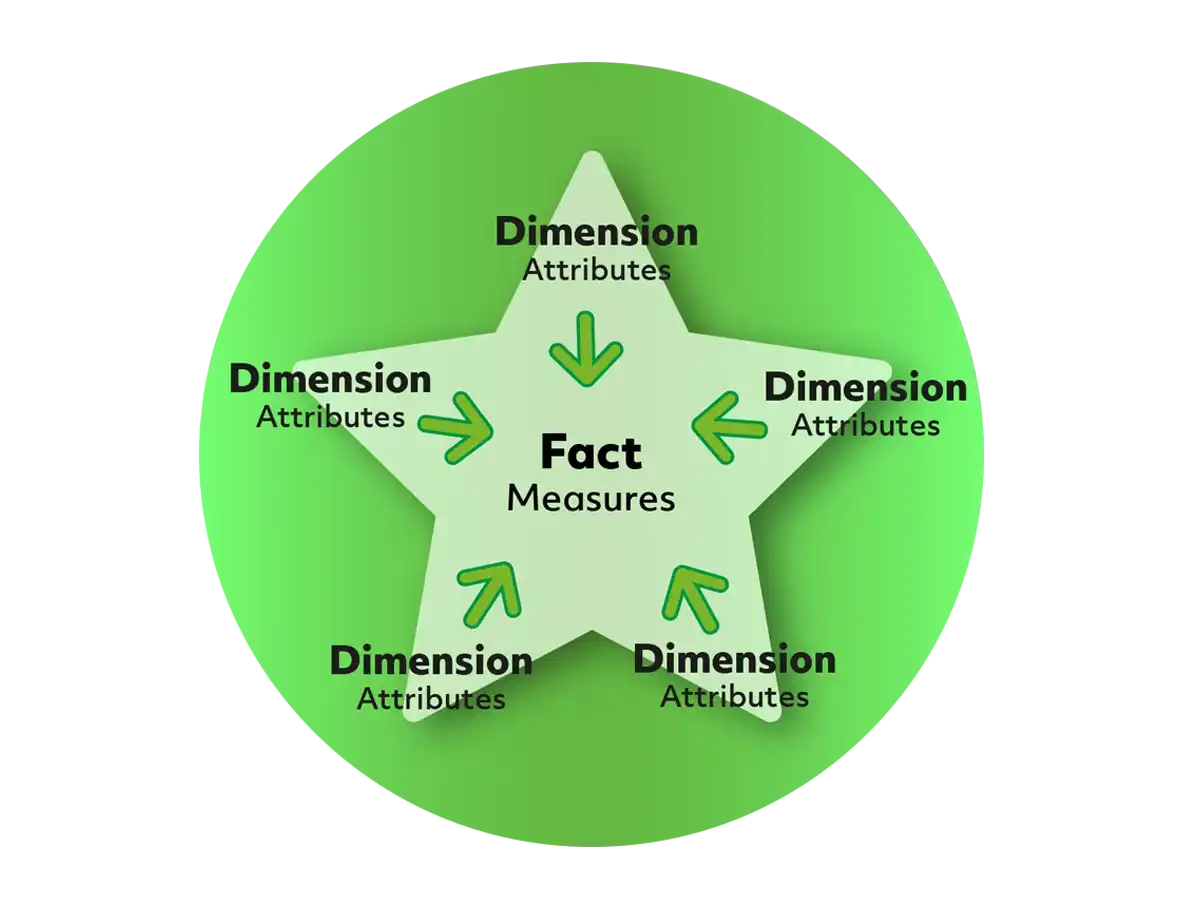
Det er vigtigt, at træffe nogle beslutninger om jeres data, inden de transformeres og loades ind i et Data Warehouse. Det begynder typisk med at identificere en forretningsproces, hvor der skabes nogle facts og dimensionstabeller. Disse loades via ETL proces i SSIS (Extract, Transform Load).
Når man har identificeret, hvad det er, der skal måles på (facts,) så bygges processen, der integrerer data fra kilder til Data Warehouse. Data hentes fra kilder (NAV, AX, CRM osv.), transformeres og loades ind i Data Warehouse. Denne proces kaldes ETL, som står for Extract, Transform, load. Processen er ikke software afhængig, det kan gøres på mange måder.
I Unit IT bruger vi SQL Server Integration Service (SSIS) samt T-SQL til denne proces, når det er on-prem. I Azure er der yderligere mulighed for at bruge Data factory (SSIS i skyen), Data Lake, Azure automation, Data Bricks osv. Typisk styres ETL flowet af et SQL-job, som så afvikler SSIS pakkerne og opdaterer Data Warehouse data.