
Et nonclustered index indeholder kun de data vi definerer, når vi opretter det. Vi har key columns, der fortæller sorteringen, og så har vi mulighed for at inkludere kolonner, så vi derved kan opfylde en SQL forespørgsel. Vi skal huske, at et nonclustered index er en kopi af vores data på nye pages. Hvorimod et clustered index er vores data og indeholder alle rækker og alle kolonner.
Det nonclustered index fylder derfor mindre, da det kun er et subset af vores kolonner. Det betyder, at det er hurtigere for SQL Serveren at finde data, da der er færre pages, der skal læses igennem. Og selvfølgelig også fordi data er sorteret, så der kan søges (seek) efter data i stedet for at scanne (scan).
Nonclustered Index filter
Vi har endnu en mulighed med vores nonclustered index. Vi kan tilføje et filter, hvilket vil sige, at vi kan sætte en simpel WHERE clause på og derved skære endnu mere ned på mængden af data i vores nonclustered index. Denne type index kaldes logisk nok et filtered index.
CREATE NONCLUSTERED INDEX <navn> ON <table> (<key>) WHERE A = AFordelen er at vi få gjort index endnu mindre ved både at skære ned på antallet af kolonner, men også antallet af rækker på vores pages.
Hvis vi forestiller os, at vi har en tabel med ordre, som er åbne og lukkede. I tabellen er der 5 mio. rækker hvor 200.000 af ordrerne er åbne. Vi søger typisk kun efter åbne ordre og meget sjældent i de lukkede. Her vil et filtered index være gavnligt. Vi kan oprette et filtered nonclustered index og derved hjælpe SQL Serveren med at skulle læse væsentligt færre rækker igennem. Det vil være en performance forbedring i dette tilfælde og også et index, der vil fylde mindre på vores disk.
Lad os prøve det af: jeg har en tabel hvor jeg smider 5 mio. rækker ind, 200.000 af dem er åbne ordre
CREATE TABLE Ordre(
id int identity (1,1),
navn nvarchar(150),
ordrenummer int,
åben BIT
)Her ses data
SELECT COUNT (*) Åben FROM dbo.Ordre WHERE åben = 1
SELECT COUNT (*) lukkede FROM dbo.Ordre WHERE åben = 0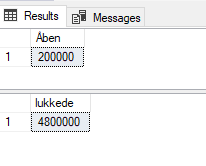
Lad os prøve at lave et par tests. Først vælger jeg alle de rækker, som er åbne på tabellen uden noget index, altså en heap table.
SELECT Ordrenummer
FROM dbo.Ordre
WHERE Åben = 1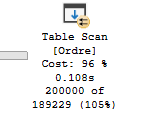
Her ses statistics. Selve forespørgslen laver 210.009 logical reads, hvilket er det antal af pages, der er læst igennem. Bemærk også, at det tager 998ms at afvikle forespørgslen.

Jeg opretter nu et nonclusttered index på åben kolonnen, inkluderer ordrenummer og kører forespørgslen igen:
CREATE NONCLUSTERED INDEX idx_ordre_åben ON dbo.Ordre(åben) INCLUDE (Ordrenummer)Jeg kan se at index benyttes:
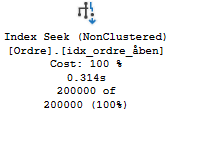
Og statistics ser sådan her ud:

Bemærk at der her kun læses 475 pages (logical reads) en væsentlig forbedring.
Nu ændrer jeg index til et filtered index og kører samme forespørgsel:
CREATE NONCLUSTERED INDEX idx_ordre_åben ON dbo.Ordre(åben) INCLUDE (Ordrenummer) WHERE (Åben = 1) WITH (DROP_EXISTING=ON)Bemærk WITH (DROP_EXISTING = ON) denne option kan vi bruge når vi vil ændre i et index, så slettes det gamle index og det nye oprettes automatisk.
Hvis vi kigger på statistics:
 Nu er der 474 logical reads. Ganske vist kun en page mindre end før (ofte er det en større ændring alt efter tabel, antal af kolonner i index osv.)
Nu er der 474 logical reads. Ganske vist kun en page mindre end før (ofte er det en større ændring alt efter tabel, antal af kolonner i index osv.) CREATE NONCLUSTERED INDEX idx_ordre_åben ON dbo.Ordre(åben) INCLUDE (Ordrenummer) WHERE (Åben = 1)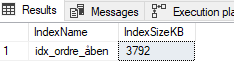
Nonclustered index (uden Where)
CREATE NONCLUSTERED INDEX idx_ordre_åben ON dbo.Ordre(åben) INCLUDE (Ordrenummer)

Resultatet af Filtered Index
Det er en markant forskel i størrelsen på de to index, og det er bl.a. her vi ser effekten af de filtered index. SQL Serveren læser altid de pages den skal bruge op i bufferen, og hvis vi kan hjælpe til med at begrænse det antal af pages, der skal læses, så hjælper vi den meget på vej. Ved at lave et filtered index begrænser vi desuden også hvor meget plads index tager på disken. Skulle du have brug for hjælp til at analysere dine index på SQL Serveren så er du meget velkommen til at kontakte mig. eller en af min dygtige kollegaer i Unit IT på tlf.: 88 33 33 33.


